The Attribution Continuum: When Heuristics Work and When They Don't
Why simple attribution rules are often right, and the specific moment they start doing damage.

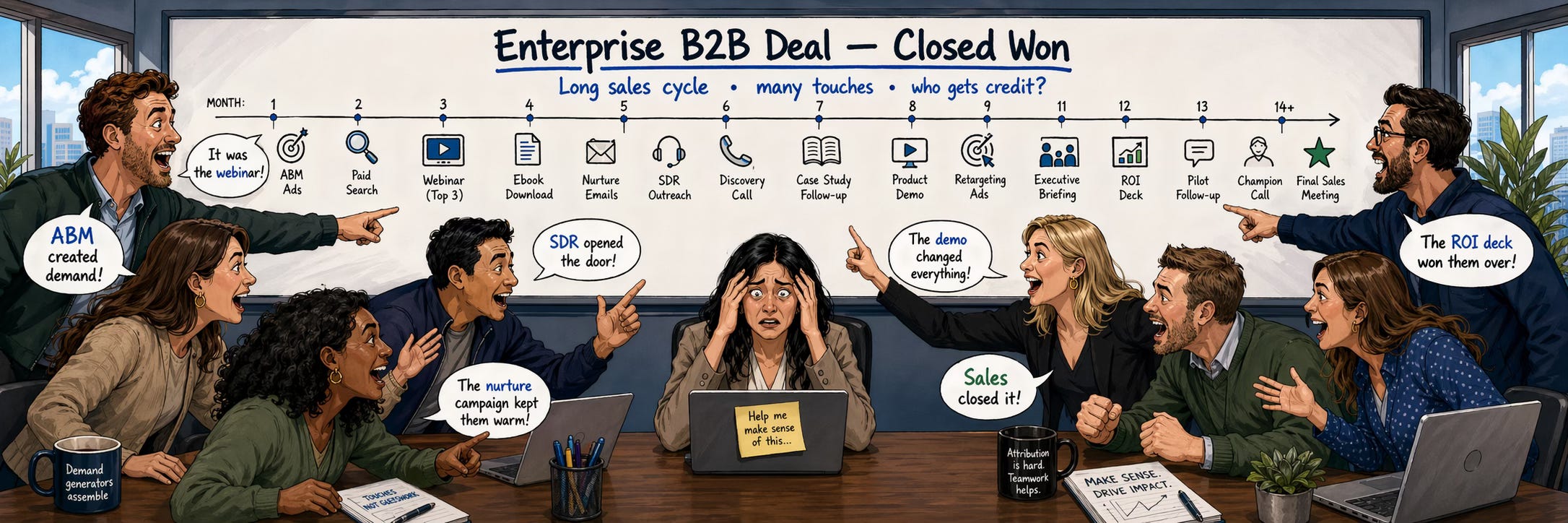
A question many marketing leaders wrestle with is how to attribute revenue outcomes in enterprise B2B, where a single closed-won deal can reflect months of activity across marketing and sales, many touchpoints, and enough complexity to make almost any retrospective explanation sound plausible. The reason this matters is straightforward: attribution is often used, directly or indirectly, to inform budget decisions. Which programs warrant more investment? Which motions are actually changing revenue outcomes? The trouble is that teams often use a method that describes the journey and then treat it as if it proved causal impact. Over time, that tends to steer money and attention toward what is easiest to measure rather than what is actually moving the business.
The stakes are real. In fiscal year 2025, Okta reported $2.61 billion in revenue and spent $965 million on sales and marketing, meaning roughly thirty-seven cents of every revenue dollar went back out the door to acquire and retain customers. That ratio has come down from forty-six cents the year before. Like most enterprise companies, Okta is likely looking for ways to spend its marketing dollars more efficiently. At that scale, even a small improvement in understanding which programs actually drive revenue can redirect tens of millions of dollars toward what works. A measurement approach that quietly rewards the wrong activities is a structural leak.
Attribution exists on a continuum, and different companies sit at different points on it. At the simpler end are heuristic rules: assign all the credit to the last touch before the deal closed, or to the first, or weigh a few key moments more heavily. These remain the most common approaches in B2B. A step up from heuristics, game-theoretic methods like Shapley values distribute credit across every touch based on its average marginal contribution across possible orderings. Beyond that, causal methods try to separate correlation from genuine impact, since a program that tends to get assigned to accounts already likely to close will look effective whether or not it actually is. Some implementations combine causal estimation with Shapley-style credit allocation; others handle the problem differently. Professor Walter Zhang at Wharton pointed me toward a working paper by Yunhao Huang that pushes on the sophistication narrative itself, finding in the context of online advertising auctions that simpler single-touch rules can produce better incentives than more sophisticated multi-touch ones. Whether the same holds in B2B is an open question, and later posts will get into what it might mean. There are also unique ideas about B2B journeys that I have not yet seen reflected in attribution models: for example, Purmonen and colleagues argued in 2023 that B2B journeys include both a purchase journey and a usage journey, and that the usage stage can feed back into new purchase cycles. I suspect some interesting work in attribution will happen here, if it hasn’t already. The rest of this post covers the first stop on the continuum: why heuristic approaches are still the right choice for many companies, and when they are not.
Before any of this is worth discussing, there is a more basic question. Do you actually have the data? Attribution of any kind, heuristic or otherwise, assumes you have a reliable record of who touched what account, when, and through which channel. In practice, most companies do not. Touch data lives in a marketing automation tool, a CRM, a sales engagement platform, an events system, and a handful of spreadsheets, and bringing it into one coherent view may not be straightforward. Before you can attribute anything, you need a centralized log of touches, timestamped, mapped to both contacts and their accounts, with the known gaps documented so you understand what the data can and cannot tell you. If you are not there yet, this is where your effort should go. A simple heuristic applied to clean data will usually beat a sophisticated model applied to messy data, and no amount of methodological sophistication downstream compensates for a broken pipeline upstream.
So what are these heuristic approaches, concretely? Take the deal in the image above. The diagram shows seventeen touchpoints over fourteen months, which is deliberately compressed for clarity; a real enterprise deal of this size typically involves hundreds of tracked touches across many stakeholders. The illustrated touchpoints include ABM ads, a webinar, SDR outreach, a product demo, an executive briefing, an ROI deck, and a final sales meeting at the end, among others. Last-touch attribution gives all the credit for this deal to the final sales meeting. First-touch gives all the credit to the ABM ads that initially brought the account in. Linear attribution splits the credit evenly across all seventeen touchpoints, so each one gets about six percent. U-shaped attribution weights the first touch and the last touch more heavily than the middle. W-shaped adds a third weighted touch at the moment the lead became a qualified opportunity. Full-path adds a fourth weighted milestone at the deal close. The exact splits across U-shaped, W-shaped, and full-path vary by vendor and by implementation, but the basic idea is the same: pick the moments you think matter most and weight them accordingly. Each model has its own logic for why it weights things the way it does, and each one produces a different picture of which channels and programs drove the deal, which is ultimately what leaders use to inform where budget goes.
It is easy to dismiss these models as too simple to take seriously. But simple is not the same as wrong, and for a lot of companies a heuristic is genuinely the right choice. If you are growing fast, closing deals, and the data pipeline we just talked about is not in place, building a sophisticated attribution engine is a way to waste several months. Each of these heuristics is also a reasonable fit for certain situations. Last-touch, for example, may work well for short-cycle direct-response businesses where the decision window is measured in days rather than months and the final touch really is doing most of the causal work. A rule everyone in the organization understands and agrees on has real value, even if it is crude. It gives marketing and sales a shared language for talking about what worked. It lets leaders make directional budget calls without waiting on a model that is not going to be ready for another several quarters. And it is cheap enough to maintain that you can reinvest the saved effort into the part of the stack that actually matters at your stage, which is usually building more pipeline. A lot of the companies that eventually graduate to more sophisticated attribution started here, stayed here longer than they would admit in a conference talk, and were probably right to.
So when do these models stop being the right choice? The usual answer is that they become inaccurate, but that misses what actually goes wrong. Ron Berman, in a 2018 Marketing Science paper titled “Beyond the Last Touch,” made the sharper argument. He was writing about online advertising, where publishers compete for credit on a user’s path to conversion, but the logic extends to B2B. The problem is incentives. When you reward people based on a rule, they optimize for the rule rather than the outcome. If last-touch gets the credit, reps and marketers compete to be the last touch, scheduling one more call right before close because it moves the credit, not the deal. If first-touch gets the credit, channels race to be the first recorded touch on as many accounts as possible, regardless of whether those accounts are likely to convert. The model stops describing behavior and starts shaping it, and the behavior it shapes is not the behavior you want.
The case for moving past heuristics is strongest once you have the data pipeline in place and no particular reason to stick with one. The incentive distortion is built into how heuristics work, not something that only shows up when things have visibly gone wrong. The next step is a model that splits credit across every contributor in a way that is harder to game. That turns out to be a well-studied problem. The Shapley value, originally developed by Lloyd Shapley in 1952 to fairly divide the payoff of a team among its members, has become the standard game-theoretic approach. Applied to attribution, Shapley assigns each touch its average marginal contribution across all possible orderings of the journey. The next post in this series walks through how it works and why it is the natural next stop on the continuum. It also has its own problems, which later posts will get into.
One more thing worth saying. The debate about which attribution model is “right” quietly assumes you are only picking a measurement tool. You are also picking an incentive system, because people optimize against whatever gets measured. The answer depends on what behavior you want to produce, not just what you want to measure.